
Расчёт отпускных. Как учесть неявки по предыдущему месту работы
Добрый день!
Сотрудника перевели с одной должности на другую. По интеграции с КП пришёл приказ на перевод, с июля человек работает на новой должности. Переводили сотрудника без выплаты компенсации за неиспользованные дни отпуска.
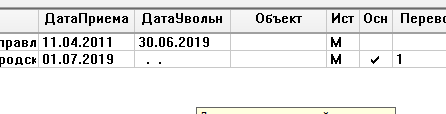
В августе требуется рассчитать отпускные данному сотруднику.
Выбираю для расчёта обе должности сотрудника, старую и новую
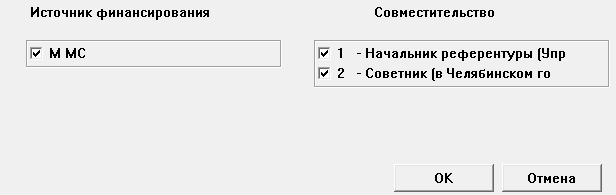
Указываю, что результат расчёта нужно разносить на новую должность:
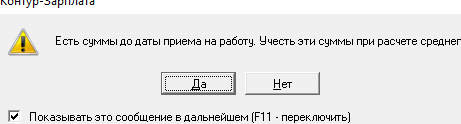
Выводится сообщение о том, что есть суммы до приёма на работу нажимаю "Да"
Рассчитывается средний заработок. При этом все 12 месяцев отображаются, как полностью отработанные сотрудником.
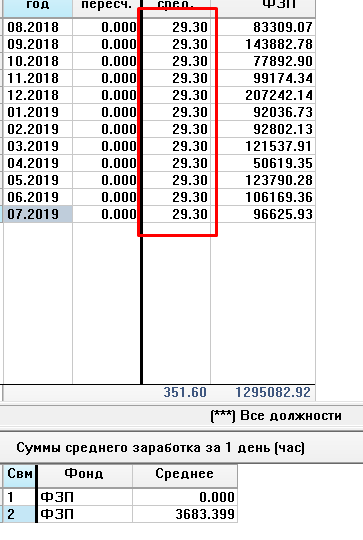
При этом, например в апреле месяце у сотрудника был отпуск. По прежней должности (с которой сотрудника перевели.
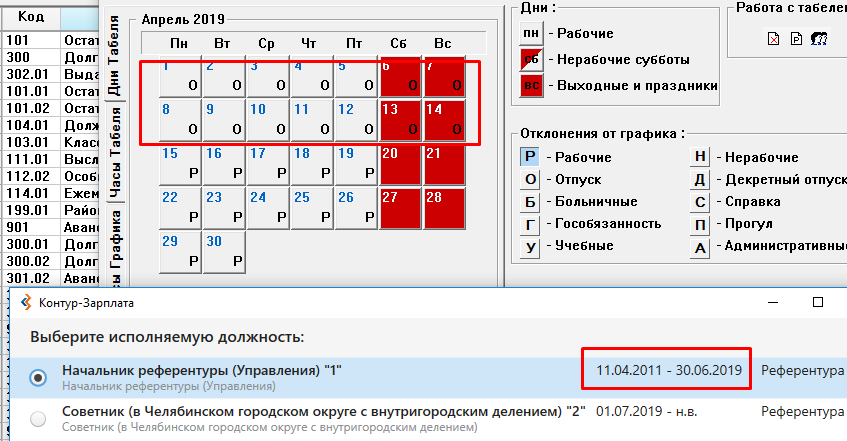
Табель по новой должности у сотрудника пустой до июля 2019 года, когда сотрудника перевели. Поэтому, получается, что при расчёте среднего все месяца программа считает полностью отработанными.
Прикладываю сохранённый ЛС.
ZPL2907_zplinfo_full(20190806_172646).cab
Подскажите, пожалуйста, как сделать так, чтобы при расчёте среднего учитывались неявки сотрудника?
Сервис поддержки клиентов работает на платформе UserEcho

Добрый день.
Нужно сначала сделать расчет по первой должности, потом по второй.
Сотрудник переведён с 1.07.2019 на новую должность.
Считаю по прежней должности:
Считаю по текущей должности:
В итоге получилось 2 отпуска, по старой должности, и по новой.
В связи с чем в глаза бросаются ошибки:
1) Из КП по интеграции приходит один (1) приказ на отпуск. Период отпуска у сотрудника не прерывался, его перевели с одной должности на другую. Поэтому и учитывать заработок сотрудника клиенту требуется целиком, на разбивая по должностям.
2) При расчёте по прежней должности за июль ставится сумма "0" и рабочие дни "29.3". Что делает расчёт среднего неправильным.
>>Нужно сначала сделать расчет по первой должности, потом по второй.
3) Расчётчик должен об этом помнить сам и вручную по каждой просчитывать? А если переводов будет пять в течение 12 месяцев?
Таким образом, рассчитывать отпуск клиенту требуется в целом по всему заработку сотрудника, а не по отдельности, и из КП информация приходит именно так.
Получается. либо ошибка в подсчёте дней для среднего, который берётся только с новой основной должности, либо весь механизм интеграции по отпускам.
Как это выглядит в КП:
Исполняемые должности:
Отпуска (какие были, такие и остались)
Каким образом рассчитывать отпуск, чтобы на выходе получились корректные данные?
Зачем в данном случае вы перевод приняли на отдельную должность? Почему нельзя было принять данные на действующую должность?
Ждите когда в КЗ будет реализована цепочка переводов, тогда средний можно будет посчитать правильно...
>>Зачем в данном случае вы перевод приняли на отдельную должность? Почему нельзя было принять данные на действующую должность?
На должность завязаны источник финансирования, категория и шифр затрат.
И клиенту требуется разбивать суммы в сводах по подразделениям, в т.ч. по одному конкретному сотруднику, если перевод был в середине месяца.
>>Ждите когда в КЗ будет реализована цепочка переводов, тогда средний можно будет посчитать правильно...
На какие сроки ориентировать клиента и как решать проблему до тех пор?
Старые виды НУ закрываете, новые открываете.
Для новых видов НУ указываете источник, ШЗ, категорию
1)Ручная корректировка среднего
2)Либо вариант озвученный выше (при переводах не плодить должности)
З.ы. идеальной программы (нажал кнопку и все заработало для всех возможных случаев ) не существует.
>>Старые виды НУ закрываете, новые открываете.
>>Для новых видов НУ указываете источник, ШЗ, категорию
Т.е. отключить интеграцию в принципе от уровня исполняемых должностей. И пусть расчётчик набивает подразделения, категории, источники и должности вручную с бумажного носителя.
>>1)Ручная корректировка среднего
>>2)Либо вариант озвученный выше (при переводах не плодить должности)
3) Если перенести (вручную или через таблицу разноски) все неявки из табеля старой основной должности в табель новой - это решит проблему с расчётом среднего. Возможен ли такой вариант, или он выйдет боком где-то в другом месте?
Интересно, а как программа узнает, что источник в ЛС сменился? Из КП разве передается подобная аналитика?
Отключать интеграцию видов я не предлагал.
Я объяснил как разбить суммы по источникам при переводе в середине месяца.
>Интересно, а как программа узнает, что источник в ЛС сменился? Из КП разве передается подобная аналитика?
Источник из КП не передаётся. С этим вопросом мы тоже не раз обращались, там проблема в том, что в КП могут при приёме разбить должность по нескольким источникам (принять на 1 ставку, но из неё 0,5 на Бюджет, 0,25 на Спецсчёт и т.д.)
В данном случае у клиента есть чёткое соответствие между должностью сотрудника и источником финансирования. Расчётчик видит, что пришла новая должность из КП, видит категорию должности (тоже передаётся из КП) и ставит на её основании источник для данной ИД.
>>Отключать интеграцию видов я не предлагал.
Если пришёл "голый" вид Н-У, в нём нет информации по подразделению, категории, источнику. Расчётчик не сможет корректно провести расчёт и выплатить суммы по этому виду Н-У, потому что не знает, на какой источник, подразделение, должность эти суммы ставить, по какому источнику их выплачивать.
Если нет ИД с этими параметрами - только ждать бумагу из кадров и с неё перебивать.
Т.е. ручная корректировка присутствует.
Выделить "новые" виды и поставить им массово источник не сильно трудозатратнее чем, поставить источник в к.ч.
Причем тут голый вид?
В к.ч.при переводе ( с даты перевода) запишется и должность и категория.
Если у вас заранее известно какая должность к какому источнику относится, то можно у видов "атоматом" проставлять нужный источник, немного допилив UserIntegrProcessVidNU()
Вы сами себе противоречите:
. Расчётчик видит, что пришла новая должность из КП, видит категорию должности (тоже передаётся из КП) и ставит на её основании источник для данной ИД.
>Т.е. ручная корректировка присутствует.
>Выделить "новые" виды и поставить им массово источник не сильно трудозатратнее чем, поставить источник в к.ч.
И потом помнить, что надо менять источник для таких-то сотрудников, если им добавляется вид Н-У. Например, разносится массово премия.
>В к.ч.при переводе ( с даты перевода) запишется и должность и категория.
А также меняется и дата приёма и дата увольнения.
(см тему:
https://kontur.userecho.ru/communities/47/topics/7637-integratsiya-s-kp-pri-nastrojke-priyoma-id-raznosit-tolko-v-kch-menyaetsya-data-priyoma-v-id
что чревато другими ошибками.
Возвращаясь к основной теме с расчётом отпуска:
>>Если перенести (вручную или через таблицу разноски) все неявки из табеля старой основной должности в табель новой - это решит проблему с расчётом среднего. Возможен ли такой вариант, или он выйдет боком где-то в другом месте?
Как вы массово разносите премии, для каждой строки в таблице указываете на какую должность поставить сумму? Та еще автоматизация...
У настройки "Способ приема Исполняемых Должностей" есть значение 2 - при котором дата увольнения не меняется.
копирование табеля в новую должность должно помочь с проблемой учета неявок
>>>Как вы массово разносите премии, для каждой строки в таблице указываете на какую должность поставить сумму? Та еще автоматизация...
Принимаем в таблицу только незакрытые должности на дату и разносим на них. Ничего проставлять не приходится.
>>У настройки "Способ приема Исполняемых Должностей" есть значение 2 - при котором дата увольнения не меняется.
Предлагаю обсуждение этого вопроса всё же перенести в указанную тему.
>>копирование табеля в новую должность должно помочь с проблемой учета неявок
Я спрашивал о другом.
Хорошо, будем надеяться, подводных камней не выйдет.
В моем понимании ошибка, это когда что-то сделали, но работает неправильно (не так как задумывали).
Отсутствие какой-либо возможности это не ошибка.
Расчет отпуска по цепочке должностей в КЗ в принципе не делался. В частности потому что большинство клиентов на интеграции не заводят отдельных должностей при переводе.
Задача такая есть. Конкретные сроки сейчас назвать не могу. С учетом того, что за последние два месяца это минимум второй "сигнал" о востребованности этой функциональности, постараемся повысить приоритет у этой задачи.
Ваш ответ понятен. Будем пока устраивать паллиативные меры с переносом табеля на новую должность, и ждать выхода нового функционала.
По поводу того, что считать ошибкой, остановлюсь отдельно.
>>В моем понимании ошибка, это когда что-то сделали, но работает неправильно (не так как задумывали).
>>Отсутствие какой-либо возможности это не ошибка.
Проблема именно в том, что до конца непонятно, "как именно задумывали".
Я постараюсь описать своё видение проблемы, прошу прощения, если как-то коряво сформулирую.
Насколько я понимаю, основная проблема кроется в том, что мы говорим о разных сценариях работы системы и пользователя.
У нас есть параметр интеграции "Способ приёма Исполняемых Должностей".
Николай говорит о том, что если поставить в неё значение "1" или "2", то описанная выше проблема не возникнет.
Не спорю, такой вариант действительно поможет. Просто сейчас для его реализации нам надо сносить половину текущего варианта системы, заново проводить синхронизацию должностей с КП, переделывать все доработки, что завязаны на должности и переучивать расчётчиков, которые за 7 месяцев привыкли к нынешнему сценарию работы. Это процесс возможный но далеко не безболезненный.
Но зачем тогда возможность поставить параметр "0", когда "каждая должность сотрудника принимается как новое совместительство"?
Если у нас есть единственно верный сценарий работы с интеграцией - когда все переводы разносятся на одну ИД, то зачем "задумывали" другие варианты? Тогда сама возможность для внедренца указать параметр "0" - ошибка.
Если же вариант с параметром = "0" - возможен, и "задумывался", то при одном из сценариев работы расчётчика ("был перевод" И "рассчитываем отпуск") мы упираемся в тупик, описанный выше. Что и является ошибкой.
Не может же так быть, чтобы вариант "принимать каждую должность как новое совместительство" - "задумывался", а последствия - "переведённому сотруднику нужно рассчитать отпуск" - "не задумывались"?
Нам не хватает развёрнутой инструкции по работе с интеграцией. С ней подобных вопросов бы не возникало в принципе